the control plane for llm inference
the control plane for llm inference
LLM inference APIs are vastly different from normal APIs, and they're also very different from inference with normal ML models.
If you built a standard web application, the data is queried by the server, and the server replies, completing the entire process in milliseconds. If you run a standard CNN model (let's say, for a classification task), the inputs have a fixed-size, the model takes a deterministic amount of time to run, and the output is also fixed-size. This makes things easy and predictable. One can use a simple HTTP API to handle these tasks.
llm inference is different
Inputs to LLMs are variable sized. They can potentially take minutes to complete (LLM inference completes by either outputting the EOS token, or by reaching the n_out limit, defined in the params). This risks HTTP request timeouts. Plus, using HTTP means you can't stream your outputs! The user is stuck waiting for an answer for minutes, and as soon as it does arrive, they see the entire answer at once.
Now, for one request, everything can still work just fine. HTTP connections can be left open for minutes, which is enough for most LLMs to complete one inference cycle. But what if 50 people hit the API at once?
thundering herd problem
Imagine a coffee shop with one barista (this is the GPU). If 50 people come in at once and all of them scream their orders at once, it's impossible for them to process this.
So, what do you do? Simple - you create a queue and you make the people talk to a cashier (the queue handler) instead of the barista directly. People line up and wait their turn, and they get tickets while waiting. When the barista is free, they serve the next person in line. The cashier is the one who directs the next person in line to the barista.
This entire process is basically what's called an event-driven architecture, in fancy terminology.
the architecture that solves this
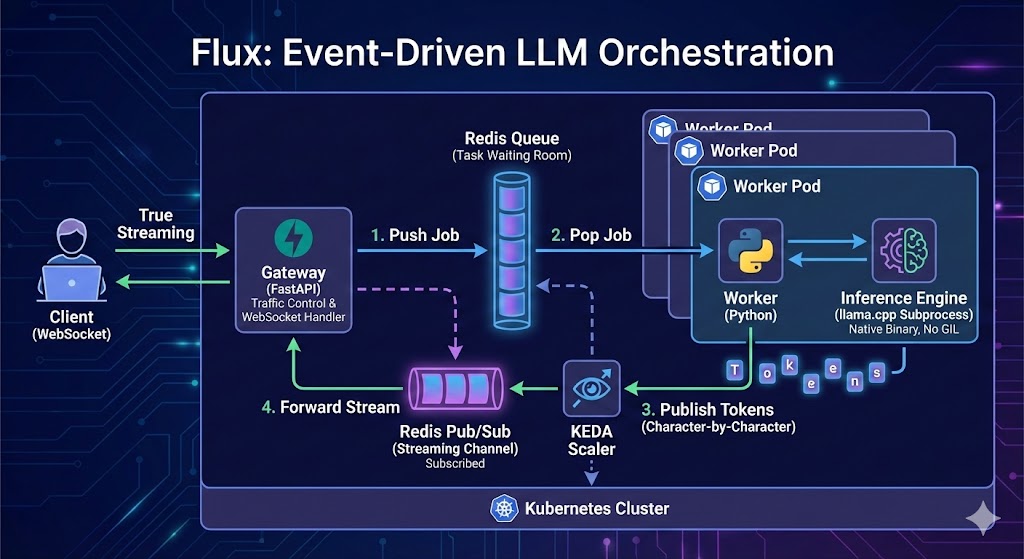
Here's the entire flow of what's going on, from the user's perspective:
- User: "Write me a poem"
- Gateway: "Cool. Here's your ticket. Please wait for your request to be served."
The gateway puts the request in a Redis queue.
# services/gateway/gateway.py
# 1. Subscribe to the unique response channel
channel = f"{CHANNEL_PREFIX}:{request_id}"
await pubsub.subscribe(channel)
# 2. Push job to the work queue
job = {
"request_id": request_id,
"prompt": prompt,
"max_tokens": max_tokens,
}
await redis_client.rpush(QUEUE_NAME, json.dumps(job))
Meanwhile, here's the backend flow:
- GPU becomes available to serve a new request.
- The worker pops the Redis queue and sends the request details (the prompt and inference params, if any) to the GPU/Inference Engine.
- The worker streams the text to the user who has the ticket.
The user stays connected, via WebSockets, and watches the text appear token by token.
llm streaming
When running LLM inference, you can't wait for the entire request to be served. You have to stream tokens one by one - giving the user the sense of "Oh, okay, something's happening".
I achieved this using Redis Pub/Sub:
- The worker runs the model as a subprocess (I used llama.cpp, not llama-cpp-python, as the latter is outdated.)
- It reads the output character-by-character.
- When a character appears, it Publishes it to a Redis channel.
- A listener (the gateway) instantly shoots it down the WebSocket connection to the user.
Crucially, reading stdout needs to happen byte-by-byte to feel "instant". Plus, by running the inference engine as a subprocess, we avoid Python's Global Interpreter Lock (GIL). Python just acts as the glue code for Redis, while the C++ binary handles the heavy matrix math without blocking.
# services/worker/worker.py
# Run llama-completion as a subprocess with line buffering
current_process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
bufsize=1,
text=True
)
# Read output character by character - TRUE streaming!
while True:
char = current_process.stdout.read(1)
if not char:
break
# Publish immediately to Redis
redis_client.publish(channel, json.dumps({
"type": "token",
"content": char
}))
scalability
There's two ways you could potentially do scaling, in LLM-based applications. One is to scale when the GPU gets overwhelmed. But this might be too late to do. By the time the new workers are created, your users have left your platform because its too slow.
The above type of scaling, in k8s terms, is called HPA (Horizontal Pod Autoscaling). Instead, I used KEDA (Kubernetes Event-Driven Autoscaling). This is better because it scales when the queue gets too long.
- queue size=0? scale down to 0 (or 1).
- queue size>X? spin up more workers immediately!
# k8s/keda-scaledobject.yaml
triggers:
- type: redis
metadata:
address: redis-master.flux.svc.cluster.local:6379
listName: llm_queue
# Scale up when > 2 jobs are pending
listLength: "2"
closing thoughts
This is just one of many optimization techniques that are commonly used to build scalable LLM inference APIs. I will be covering more in the coming weeks.
resources
- Code Repo for Flux — The repository containing all the code in this project.
- Minikube - minikube start